When I first heard about GenStage and Flow my thought was to use it in a photo processing project that I had on the backburner. With so many photos to manage, and not just digital pictures, but scans, original art as well as older digital photos with sketchy data attached. I’ve never been happy with the organizing tools available in the cloud photo services, and I’ve never been particularly happy about sharing/entrusting my data to them. So I began investigating using Flow for my photo triage workflow. My first pass at this workflow requires the following steps for each image file:
- Generate a hash for each file
- Check in the database if an image with the same hash was already present, if not add the image as a Photo record. Reject it if it’s already there.
- Read the file info for the image
- Read all exif data if present
- When exif data is present, and contains location data, use the data to determine the photo location through the GeoNames service.
- If the location was not already in the database add it as a Place record and associate the photo with it.
- Persist all file info and exif data along with our Photo record in the database.
While a pretty simple set of functions, it did have some interesting lessons to teach regarding Flow and multiple processes interacting. Since the code in these operations is all pretty unremarkable I will instead elaborate on a few solutions to these issues I found helpful. All code is located in this github repository, so follow along if you wish. Feel free to post comments or questions there and I can try and help out.
Codify the data transport
In my app I created a FlowPhoto Struct to represent the data as it flowed through all steps of the flow. It was a big convenience to not be wondering what structure was being passed to what step in the flow, and it provided a lot of utility over just passing a map. A small code sample looks like this:
defmodule PhotoFlowExample.Flows.FlowPhoto do
defstruct original_path: "",
hash: nil,
photo: nil,
place: nil,
geodata: nil,
exif_info: nil,
file_info: nil
def from_path(s) do
LoudCounter.increment_tag(:ingested, 1)
%FlowPhoto{
original_path: s,
}
end
def add_hash(%FlowPhoto{} = fp, hash) do
LoudCounter.increment_tag(:hash, 1)
%{fp | hash: hash}
end
def add_file_info(%FlowPhoto{} = fp, %FileInfo{} = info) do
LoudCounter.increment_tag(:finfo, 1)
%{fp | file_info: info}
end
# etc, etc,
end
From the code you can see this not only gives me a single place to implement my logging, but also provided an easy way to do pattern matching to control the Flow in later stages. As shown here:
defmodule PhotoFlowExample.Flows.Geonames do
...
def persist(%FlowPhoto{geodata: nil} = item), do: FlowPhoto.set_place(item, nil)
def persist(%FlowPhoto{geodata: geodata} = item) do
FlowPhoto.set_place(item, Places.fetch_or_create_place(geodata))
end
def persist(item), do: FlowPhoto.set_place(item, nil)
...
Partitioning
How you partition the data flow and the number of stages you provide will have the greatest effect on your results. The partitions, and the number of stages you place in each partition determine how many different workers will be used to process your flow. I did find a correlation between adding stages and faster results, however adding too many stages hurt performance on lower end hardware like the RPI3. So keep in mind some of these performance tweaks are very much dependent on your individual needs. In my case I settled on 5 stages since it worked pretty well anywhere and overall speed isn’t of the utmost importance. The first chart is the photo flow with no partitioning at all. In this case the photos move through the flow one at a time. The second and third charts show the results when partitions are used with 3 stages and 6 stages each. Stages represent the number of worker processes receiving items in that particular partition. Note that both of these examples were much faster than the unpartitioned flow, but pretty close in speed to each other.
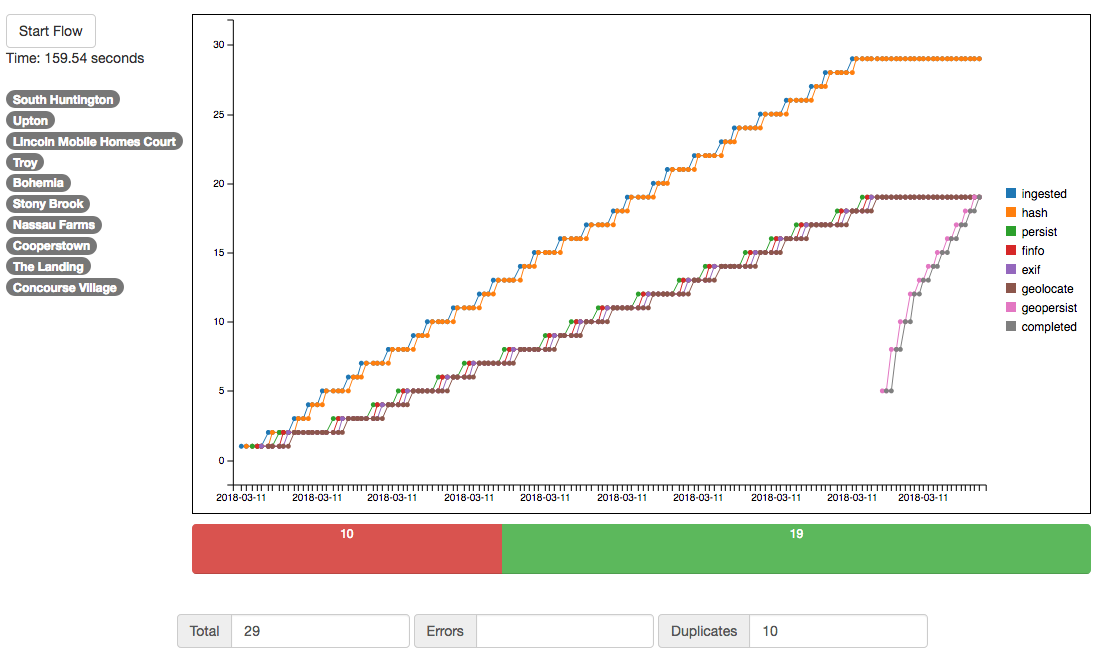
No partitioning
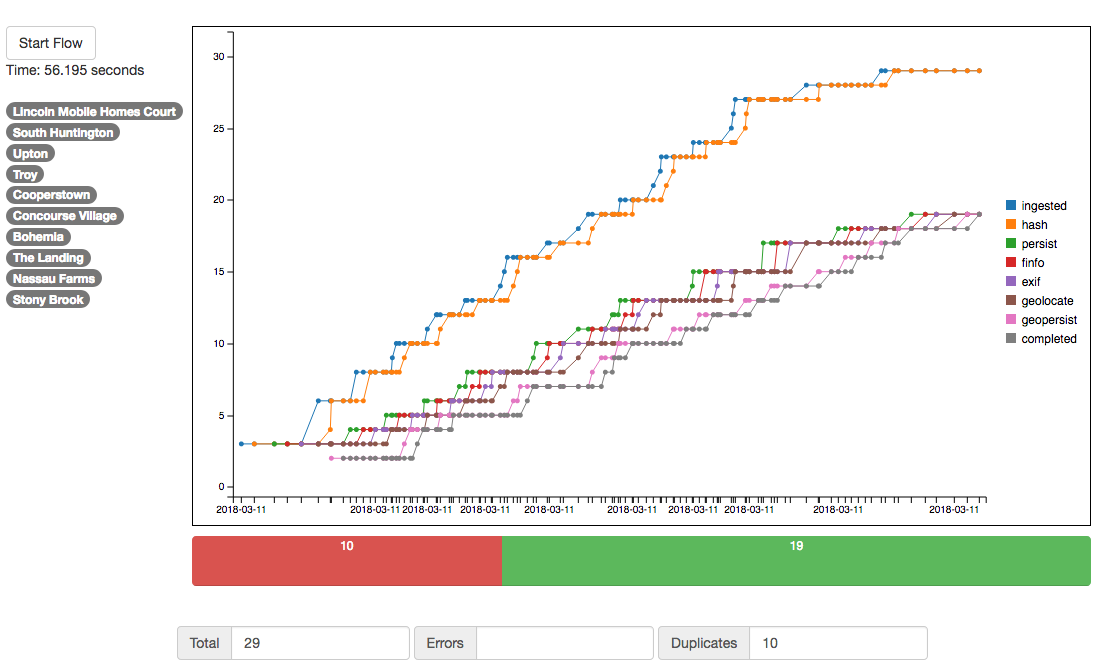
3 stage partition
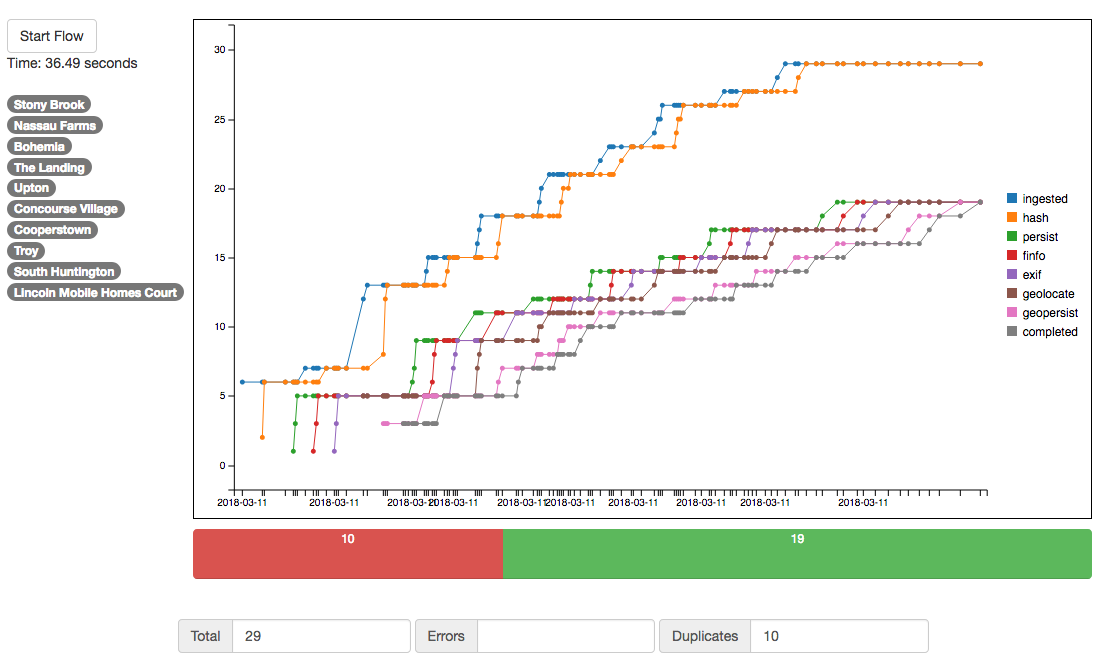
6 stage partition
Peristance Issues
During the testing of various partitions I did come across some issues, mainly about database persistance. I have two places in my Flow where I need to create a database record and they each have constraints which, if not taken into account, will result in incorrect data being amassed. The problem arises when you want to check if a given record is already in the database, and create it if it isn’t. Due to elixir’s preemptive multitasking it is very likely that two processes could look for the record at the same time, and not finding it, each would then create it. The sample program had two places where I’m persisting data; first is in creating a Photo record for image in the database, and the second involves persisting the a Place record associated with the photos location. Each of these proved to have a different solution.
Trust in unique indexes
Since the photo creation issue comes up in a situation where I am always adding a Photo, I decided to let the database take care of this for me. The first step of the flow is to compute a hash for the photo, which should uniquely identify the data in the file. Since this value was specified in the database schema as a unique index, Ecto will return an error when I try to add a duplicate. No more processing of the image is to be done in this case, so it seems like a good solution. After that step I can just test if there is a Photo record attached to the data and if not, reject the Photo from further flow processing. In the other instance this was not the case. While I still do not want duplicate Place records in the database in most cases I won’t be creating many new ones. Most of the places I take pictures I’ve already been to! It just seemed wasteful to always try and create a Place when most of the time its expected to fail. So for this case I instead could let the Flow handle it. I did this by repartitioning the Flow but this time using the geo_code value returned from GeoNames as a partition key. The partition key makes sure that any photos in the Flow at the same time and having the same geo_code will be routed to the same Process. This way I don’t have to worry about different processes both creating a Place record in the db at the same time. The little bit of code to do that is shown here and works quite well:
...
|> Flow.map(&Geonames.fetch(&1))
|> Flow.partition(stages: 5, key: {:key, :geo_code})
|> Flow.map(&Geonames.persist(&1))
...
defmodule PhotoFlowExample.Flows.Geonames do
...
def place_key(%FlowPhoto{geodata: nil}), do: ""
def place_key(%FlowPhoto{geodata: geodata}) do
"#{geodata["geonameId"]}"
end
...
end
Rate Limiting
The GeoNames service limits the number of calls you can make to their server. While I worried that this was going to cause a problem, of course in Elixir the solution could not be easier! I used the Hammer package to provide a windowed counter, allowing me to determine if I was still within the query limit. In case the request is over the rate limited value, in true BEAM fashion, I just sleep the process and then try again. This blocks the process until the window is open again but of course doesn’t affect the overall app operation. Runtime errors returned from GeoNames are handled the same way, just wait a bit and try again. Another huge win for elixir!
defp do_locate_place(lat, lng) do
case ExRated.check_rate("geonames/find_nearby_place_name", @six_minutes, 60) do
{:ok, _cnt} ->
try do
%{"geonames" => [geo_data]} = Geonames.find_nearby_place_name(%{lat: lat, lng: lng})
geo_data
rescue
_e in RuntimeError ->
Logger.warn "Geonames RuntimeError, timing out naming"
Process.sleep(@two_minutes)
do_locate_place(lat, lng)
end
_ ->
Process.sleep(@two_minutes)
do_locate_place(lat, lng)
end
end
Document Your Flow
Almost all of the documentation I have read concerning Flow mentions that you need to know your processes, to which I would like to add that you know your goals also. Is overall speed paramount? Is conserving resources something you are more concerned about? Knowing where you stand on issues like this will save you a lot of needless fiddling while building your app. In any case knowing exactly whats going on is very important. So important I believe a future release of Phoenix will focus on metrics. But in my case I had to roll my own using a GenServer, a channel constructed to send an update message to any clients every second when the underlying data had changed, and the wonderful C3.js library for charting. Starting from the easy side first the C3 javscript neccesary to build the charts you see here is:
var lineChart = c3.generate({
bindto: '#timeseries',
legend: { position: "right" },
data: {
json: [],
keys: {
x: "time",
value: ["ingested", "hash", "finfo", "exif", "persist", "delete", "geolocate", "completed"]
}
},
axis: {
x: {
type: 'timeseries',
tick: { format: '%Y-%m-%d' }
}
},
type: "timeseries"
});
# and in my socket code
channel.on("refresh", payload => {
lineChart.load({
json: pyld.history,
keys: {
x: "time",
value: ["completed", "delete", "exif", "finfo", "geolocate", "hash", "ingested", "persist", "geopersist"]
}
});
});
The Genserver just counts along as each photo moves through a step and the channel checks every second to see if the data has changed and broadcasts it if so.
def handle_info(:start_shouting, socket) do
broadcast_tags(socket, LoudCounter.different_tags)
Process.send_after(self(), :start_shouting, 1000)
{:noreply, socket}
end
defp broadcast_tags(_socket, tags) when tags == %{}, do: :ok
defp broadcast_tags(socket, tags) do
broadcast!(socket, "refresh", broadcast_format(tags))
end
The short summation of my efforts is that it was very easy to get the flow up and working correctly. After that it quickly becomes an issue of tweaking the various parameters for optimum performance, if thats even necessary. It leaves you with an efficient, flexible, easily maintainable and easily exxpandable code base that handles most of the hardest part of mutlithreaded proceessing for you. A huge success for sure. Finally, I've uploaded my first real test process (1000 photos, most with location data) in the video below. Note that the rate limiting for the GeoNames service was the main driver of execution speed. For convenience sake I trimmed the timeouts from the video, with the actual time for the process taking a little over an hour and a half.




